G’day guys!
If you’ve been following my blog for a while or happen to know me in person, you’ll know that I’m a big advocate of certifications. They can be a bit divisive, but you can read my arguments for getting certified here. Anyway, I’ve been knee-deep in ElasticSearch for a while, and since I finally passed the Elastic Certified Engineer exam last November, I decided to dedicate 2024 to security and secure coding. I’m thinking once every couple of weeks, I’ll do a little write up of whatever secure coding topic I’m looking into and put it up here, just for the unlikely event that it benefits someone else - or to remind myself of some detail if I’ve forgotten about it later. Our first topic: CRLF injection, aka Newline Injection!
CRLF-a-what now?
Just in case you’re not familiar with the acronyms, CR refers to a Carriage Return (the \r escape character) and LF refers to a Line Feed (the \n escape character). But I find CRLF Injection to be a bit of a mouthful, and Newline Injection seems to roll off the tongue a bit easier.
Wait, you’re telling me that new lines are dangerous?
Kind of. Just try to imagine all of the different things that contain a semantic new line, especially in the context of web applications. That is to say, things where a new line carries some kind of meaning to the system that interprets it.
Server Logs
Your application server logs will of course vary to some extent, but chances are they’ll look something like this. The important thing is that, they’re (typically) separated by a new line such that each distinct line indicates a new distinct log message.
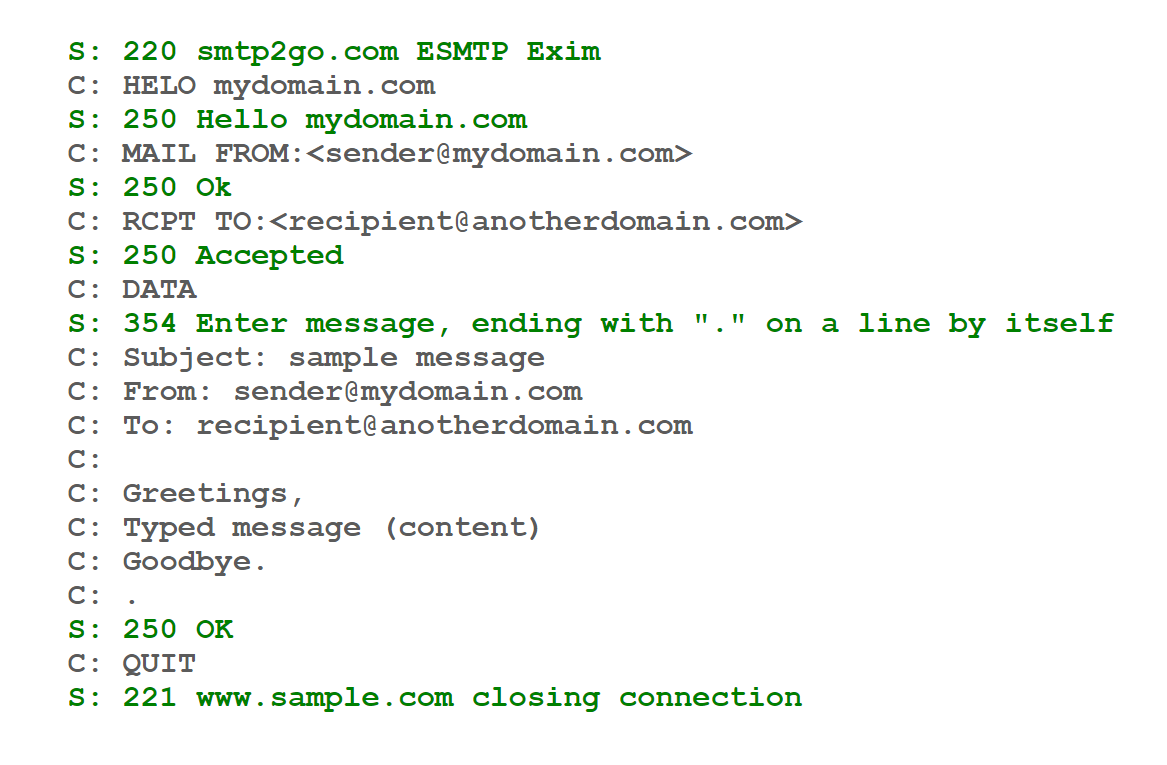
SMTP Messages
As shown below, SMTP messages (at least, the payload that’s sent after the initial handshake) have headers such as subject, from, to, etc separated by newlines.
In fact, this probably sounds awfully familiar to another common protocol used in web technologies…
HTTP Messages
HTTP messages (both requests, and responses) also contain headers that are separated by newlines.

Fair enough. So what makes this a problem?
Let’s just imagine that we have a web application that allows users to publish blog posts, and the response for viewing a blog post looked something like this:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 1234
X-Author: John Doe
...
Here, the application is returning the name of the author of the post in the X-Author HTTP header. The name of the author is of course entered by the user at some point, so just imagine if instead of submitting John Doe, they submit:
John Doe\r\n\r\n<script>alert('You\'ve been hacked!');</script>
The extra two lines after the fake user name would cause whatever follows to be interpreted as the start of the HTTP response body, and then rendered by the browser. Just imagine what our mischievous friend John could include instead of the innocent alert we’ve demonstrated here. This particular exploit, when applied to HTTP response messages is referred to as HTTP Response Splitting.
This sort of vulnerability, in theory, applies to anything that uses newlines in a meaningful way. In the case of an SMTP message, if the message contains a user-submitted value in the subject for example, a bad actor could use newline injection to include a Reply-To header, or provide their own message body. Or in the case of server log messages, a bad actor could include newline characters to add their own fake log messages to the log file.
Hold up, shouldn’t my framework or client library handle this for me?
In my limited amount of testing (in NodeJS), I did find that most client libraries, along with the Express framework did protect against this sort of attack. Having said that, it’s probably not a good idea to rely on your client library, since you never know if/when a bad commit might get pushed which introduces a regression in the client library. In fact, this sort of thing did indeed happen in NodeJS.
So what’s the answer?
I’d like to think about Newline Injection the same way we think about SQL Injection, which I think is a much more understood and accepted injection attack. Whenever we’re dealing with an SQL query, we need to keep SQL Injection in the back of our minds and make sure that we’re using parameterized queries to avoid any security holes. In the same way, whenever we’re dealing with systems that involve a semantic newline, such as logging frameworks, SMTP and beyond, we need to make sure that we’re handling newline characters correctly. A simple approach might be to just url-encode any dynamic components. This would mean that any \r\n characters would be replaced with %0D%0A and simply be displayed as such, instead of literally producing a new line in the message.
Can’t we replace newlines instead of url-encoding them?
One alternate strategy might be to replace \n characters with a space, instead of url-encoding them. There are a few reasons why I think url-encoding is the preferable solution:
-
There are some instances where we expect user input to contain new lines - eg: multi-line text fields. We certainly don’t want to accidentally replace those valid new lines with spaces.
-
If someone is submitting potentially malicious newline characters, I’d prefer to see that show up in our application logs so we can respond appropriately, rather than have the attack be silently converted into normal-looking data.
-
There could also be other potentially harmful characters in the input field. Doing a replace would only protect against newline injection, whereas url-encoding should protect against a wider range of attacks. That’s not to say url-encoding is a silver bullet, but I still think it would handle more cases than a simple replacement of
\n.
Anyway, I think that wraps up my thoughts on newline injection. This is by no means an exhaustive summary, so if you can think of any other exploits that I haven’t mentioned or have anything else to add, please feel free to let me know in the comments. Until next time!
Catch ya!